【投机解码专题】核心论文-1: Speculative-Decoding-Fast-Inference-from-Transformers-via-Speculative-Decoding
投机解码(Speculative Decoding)的核心思想,在 2022–2023 年间由 Google Research 和 DeepMind 两个团队几乎同时独立提出,代表性工作分别是:
- “Fast Inference from Transformers via Speculative Decoding”(Leviathan et al., 2023)
- “Accelerating Large Language Model Decoding with Speculative Sampling”(Chen et al., 2023)
两篇论文共同奠定了这一方向的理论基础,本文笔记以第一篇(Leviathan 等)为主线展开。
🚀五分钟全景图
一句话概括:
本文提出了一种投机解码方案:先用一个极轻量的“草稿模型”并行生成多个候选 Token,再由目标大模型做一次性验证。在输出分布数学上严格不变的前提下,将 Transformer 推理速度提升了约 2~3 倍。
创新点 (Contribution):
- 分布无损加速:与知识蒸馏或剪枝不同,本文设计的“投机采样”算法,在数学上严格保证了最终采样分布与大模型原生分布完全一致,做到了“加速但不改输出”。
- 开箱即用:无需改动大模型架构或重新训练,直接复用现成的小模型作为草稿即可。
- 模型无关:适用于任意自回归架构(T5、LaMDA、GPT 等)。
启发 (Inspiration):
- 工程实践: 在显存带宽受限(Memory-bound)的场景下,通过增加计算并发度(Compute Concurrency)来换取延迟降低是极其有效的策略。
- 模型协作: 本文开启了“大小模型协同推理”的新思路。小模型负责快速生成候选,大模型负责精准验证,分工明确。
1. Introduction
当前主流的基于 Transformer 的自回归 LLM,在解码阶段面临一个根本性瓶颈:生成 K 个 Token 需要串行执行 K 次前向传播,模型越大,单步延迟越明显。
但论文中有一个关键的观察:并非所有解码步骤都同样困难。有些位置的预测几乎是确定性的(比如“喜马拉雅山”),而有些位置则面临较大的不确定性(比如“世界上最高的山”,候选词还可能是“树”“人”“动物”等)。这意味着,如果有一个轻量级模型能先“猜”几步,再由大模型一次性确认,就有可能跳过一部分串行开销。
受 CPU 设计中“投机执行”思想的启发,论文将此思路迁移到 LLM 推理中:用一个高效的近似模型(草稿模型)先生成多个连续的候选 Token,然后让大模型并行验证这些候选,只保留那些符合大模型分布的结果。

图 1 展示了一个具体示例:一个 6M 参数的草稿模型生成了若干候选 Token(绿、红、蓝三色),随后 97M 的目标模型一次性完成验证。其中,绿色 Token 被目标模型接受,红色 被拒绝,而 蓝色 Token 由于位于首个被拒绝 Token 之后,也被一并丢弃。
在 T5-XXL(11B)上的实验表明,该方法可获得约 2~3 倍的端到端加速。
2. Speculative Decoding
2.1 Overview
流程:
- 使用草稿模型
- 使用目标模型
- 如果第 t 个 token 被拒绝了,那么第 t 个 token 就以
2.2 Standardized Sampling
为了后续数学证明的严谨性,将 Top-k, Nucleus, Temperature 等采样策略统一视为从调整后的概率分布中采样。
2.3 Speculative Sampling
本节是整篇论文的理论核心。Algorithm 1 结合附录 A.1 给出了一个关键证明:采用投机采样策略后,最终被接受的 Token 的边缘分布,与直接使用目标模型采样完全一致。

验证阶段的核心逻辑如下:
- 若
- 若
- 一旦某个 Token 被拒绝,则从修正分布
分布一致性证明
某个 Token x′ 被最终采样的概率,由两部分组成:(1)作为草稿模型的候选被直接接受;(2)草稿候选被拒绝后,从修正分布中重新采样选中。
把 (3) 带入 (2)
调整后的概率等于
把 (6) 带入 (5)
最后再把 (4) 和 (7) 都带入 (1)
这说明,投机采样的最终输出分布与目标模型原生分布 完全一致,没有任何近似或偏差。
具体举例说明
假设在某个位置,草稿模型
| token | 草稿模型 q(x) | 目标模型 p(x) | 投机采样最终概率 P(x) |
|---|---|---|---|
| A | 0.8 | 0.4 |
因为 |
| B | 0.1 | 0.3 |
只有选中 token A 才可能被拒绝, |
| C | 0.1 | 0.3 |
|
3. Analysis (理论分析)
3.1 Number of Generated Tokens (生成 Token 数量)
这一节分析单轮迭代(草稿生成 + 大模型验证)能产出多少个 Token 的期望值,它是后续加速比公式的理论起点。
论文假设各位置的接受率
那么,生成 token 数量的期望为:
- 至少生成 1 个 token 的概率是 1(必然事件)。
- 至少生成 2 个 token 的概率等于第 1 个猜测被接受,即
- 至少生成 3 个 token 的概率等于前 2 个猜测都被接受,即
- ……
- 至少生成
因此:
这是一个标准的等比数列求和,首项为 1,公比为
- 当
- 当
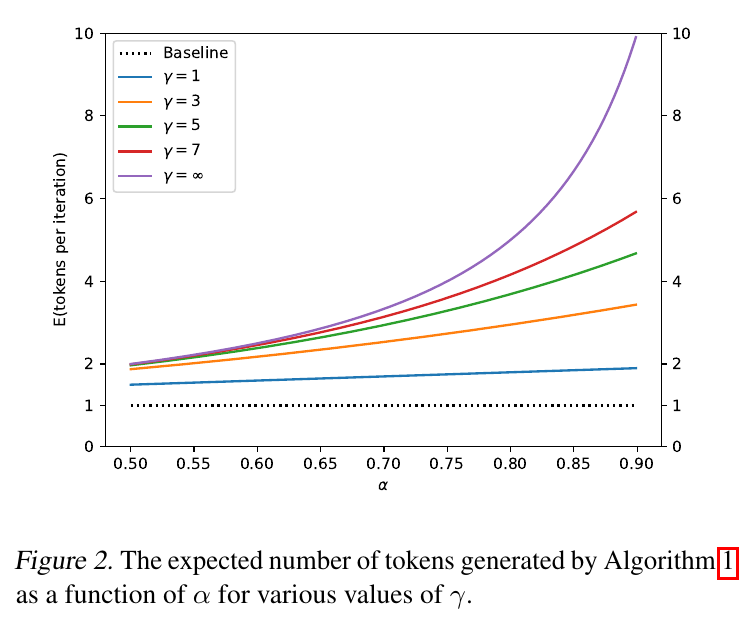
Figure 2 是以
- 投机解码的收益高度依赖于草稿模型的质量:当
- 边际递减效应明显:对于固定的
3.2 Calculating
引入
推导出
3.3 Walltime Improvment (延迟提升)
引入成本系数 c 它等于草稿模型与目标模型单次推理时间的比值:
获得总加速比:
-
-
3.4. Number of Arithmetic Operations (计算量分析)
在投机解码中如果 token 被接受了,那么在没有额外增加计算量的情况下 “免费” 获得了 token;如果 token 被拒绝,那么草稿模型对于被拒绝 token 的计算量就是额外的成本。
另外 Decoding 是访存密集型场景,就算增加计算量来换取减少内存带宽的占用也是值得的。 因为 LLM Decoding 阶段主要时间在搬运权重(读显存),而不是计算。并行验证 5 个 token 搬运权重的次数和验证 1 个是一样的。
3.5. Choosing
(1) 优化的目标函数(核心准则)
寻找最优
这里存在一个明确的权衡:
- 分子(
- 分母(
因此,最优
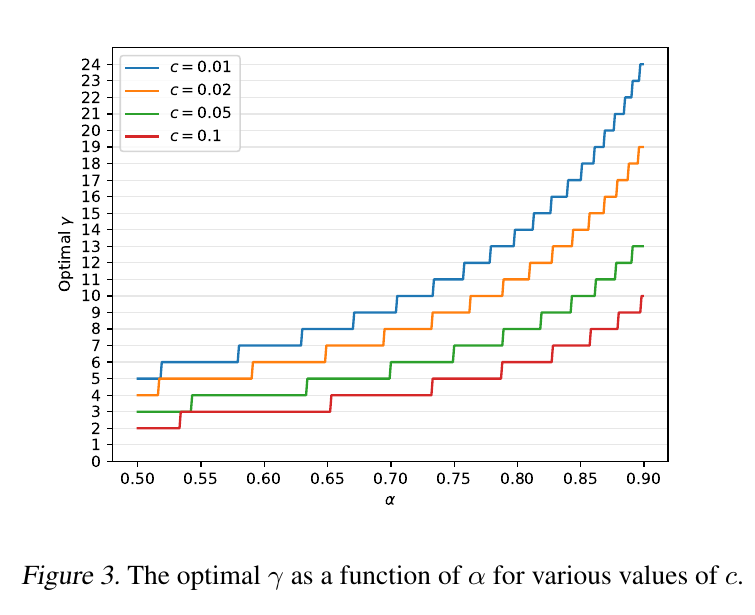
(2) Figure 3 的工程启示
Figure 3 展示了不同 c下最优
-
-
(3) 核心洞见:固定
这是 3.5 节最具前瞻性的分析。论文指出:
在整个推理过程中,接受率
并不是恒定的(因上下文而异)。某些前缀下小模型极准( 很高),某些前缀下小模型极差( 很低)。
如果全流程死守一个固定的
- 在“简单前缀”下,
- 在“困难前缀”下,
(4) “预言机(Oracle)”上界分析
为了量化动态调整的价值,论文假设存在一个完美的预言机(Oracle),能提前预知当前的
在这种情况下,期望生成的 token 数将退化为:
(这是几何分布的无记忆期望,不再受
论文进一步量化:相比于固定
(5) 论文的最终立场
尽管动态
3.6 Approximation Models(近似模型选择)
论文讨论了以下几类草稿模型的选择:
- 小 Transformer: 参数量比大模型小 2 个数量级效果时,能在 c 和
- N-gram: 极低成本的模型也能提供微弱加速(
- 非自回归模型: 也可以作为草稿模型。
4. Experiments
4.1 Empirical Walltime Improvement
实验设置
- 目标模型: T5-XXL 参数量 11B
- 任务:
- 英译德(WMT EnDe)
- 文本摘要(CNN/DailyMail)
- 草稿模型:T5-SMALL(77M),T5-base(250M), T5-large(800M)
- 采样策略: 贪婪 argmax(temp=0), 标准随机采样 (temp=1)
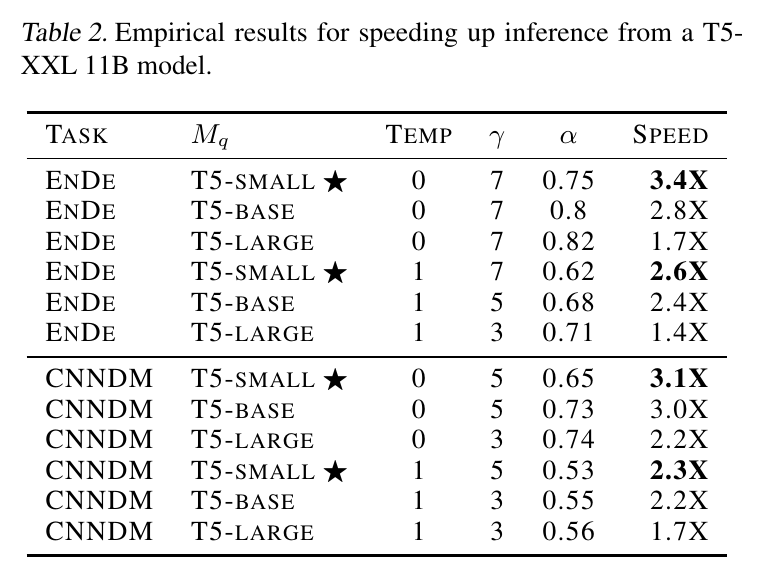
实验总结:
- T5-Small 作为草稿模型效果最好(平衡了速度和准确率)。
- 加速比: 2.6X (采样) 到 3.4X (贪婪搜索)。
- 实测结果与理论公式(Theorem 3.8)吻合。
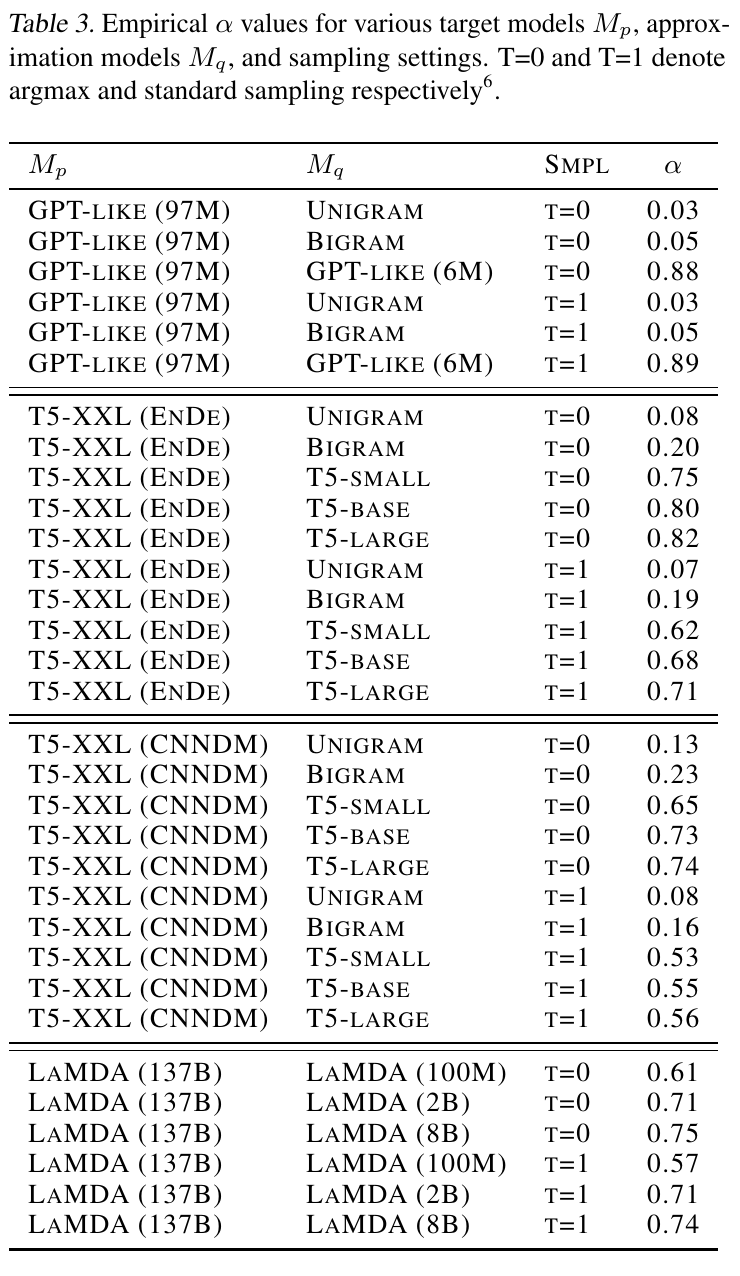
4.2 Empirical
实验不同类型的草稿模型的
- 与目标模型架构相似的小模型可以获得较高的
- 即使是 Unigram/Bigram 这种弱模型,\alpha 也有 0.05-0.20,说明只要有相关性就能加速。
5. Related work
- 自适应计算 (如 Early Exit): 通常需要修改模型结构或重新训练,本文无需任何改动。
- Blockwise Parallel Decoding: 只能做贪婪搜索,且需要训练辅助头。本文支持采样,且无需训练。
- 知识蒸馏: 会改变输出分布。本文在数学上保证了分布不变。
6. Discussion
局限性
投机解码的本质是用额外计算换取延迟降低,因此要求硬件有足够的并行计算余量。如果 GPU 利用率已接近饱和,该方法不会带来收益。
值得关注的后续方向
- 将投机解码与 Beam Search 结合(论文附录 A.4 指出会有一定性能损失);
- 训练专门以最大化
- 层级化投机:用更小的模型加速草稿模型本身;
- 跨模态推广(如图像生成等非文本自回归任务)。