【投机解码专题】核心论文-2: Accelerating-Large-Language-Model-Decoding-with-Speculative-Sampling
“Accelerating Large Language Model Decoding with Speculative Sampling” 是投机解码核心论文解读的第二篇论文,它同样是由 Google DeepMind 团队与 2023 年发表的。 它和上一篇 “Fast Inference from Transformers via Speculative Decoding” 的区别是,上一篇论文更关注数学证明与分析,这篇论文更关注分布式部署与工程优化。
🚀五分钟全景图
一句话概括:
这篇论文提出了一种名为“投机采样”(Speculative Sampling, SpS)的算法,通过引入一个更小、更快的“草稿模型”来并行生成多个候选 token,再由大模型(目标模型)进行一次性验证,从而将大语言模型的解码速度提升了 2-2.5 倍,且理论上不损失生成质量。
创新点 (Contribution)
- 无损加速:与蒸馏或量化不同,SpS 在数学上证明了其生成的分布与目标模型完全一致(在硬件数值精度范围内)。
- 打破内存带宽墙:利用并行计算的优势,将多次串行的内存读取(Auto-regressive)转化为一次并行的矩阵运算,有效突破了 Transformer 推理中的内存带宽瓶颈。
- 工程友好:不需要修改目标模型架构,也不需要重新训练大模型,只需训练一个小的草稿模型即可即插即用。
启发 (Inspiration)
- 推理架构新思路:在追求模型压缩(量化/剪枝)之外,通过“大小模型协同”的算法层面优化也是提升推理吞吐的关键路径。
- 硬件感知算法设计:算法设计必须考虑硬件特性(如 TPU/GPU 的内存带宽 vs 计算能力),SpS 正是利用了“并行打分”与“串行采样”在延迟上的差异。
- 适用场景:对于延迟敏感型应用(如对话),SpS 提供了极佳的优化方案,特别是当草稿模型与目标模型在同一硬件拓扑上部署时。
1. Introduction
基于 Transformer 架构的自回归模型在采样的时候是典型的内存带宽密集型计算。
论文提出了一种名为“投机采样”(Speculative Sampling, SpS)的算法, 来加速自回归模型的计算。
- 用一个小模型(Draft Model)自回归地生成 K 个草稿 token。
- 用大模型(Target Model)并行对这 K 个 token 进行打分。
- 通过改进的拒绝采样,按概率接受或重采样草稿 token,最终产出分布与目标模型一致。
2. Related Work
现有方法:量化(Int8/Int4)、蒸馏(Distillation)、多查询注意力(Multi-query Attention)。这些方法通常涉及精度损失或架构修改。
并行采样:Block parallel sampling 等工作,但通常只适用于贪婪搜索(Greedy)或特定模态(如图像),同时也无法适配分布式部署。
3. Auto-regressive Sampling

算法 1 2 对比了自回归采样和投机采样流程,SpS 的算法原理与上一篇论文 “Fast Inference from Transformers via Speculative Decoding” 是一致的,就不再赘述。
4. Speculative Sampling
4.1 Conditional Scoring
投机采样在验证阶段,目标模型需要并行验证 K 个 (一小段) token 的 Logits,论文称此操作的延迟与单token采样相近,前提是K较小且场景为访存密集型。
Transformer 大模型的推理时间由三部分构成:
- 线性层:Transformer 中计算 QKV 还有前馈网络(FNN) 都包含密集的矩阵乘法运算,因为涉及到大量的参数,小 batch 下,线性层处理少量 embedding,矩阵乘法受内存带宽限制。并行验证 K 个 token 与单独预测一个token的耗时相近。
- 注意力机制:这部分也是访存密集型计算,因为大量的 KV Cache 参与到计算,KV Cache 的长度不会随着 K 的大小发生改变,所以这部分也不会增加计算延迟。
- All-Reduce(通信):在分布式部署环境中,只有少量 token 的激活值需要在网络中传输,主要还是受网络延迟限制,而不是带宽限制。所以这部分也不会增加计算延迟。
4.2 Modified Rejection Sampling
通过修改拒绝采样时的概率分布,保证了投机采样结果的概率分布与目标模型是一致的。 这部分的数学原理与上一篇相同,不再赘述。
5 Choice of Draft Model
实现草稿模型的方法
- 草稿模型集成进目标模型,在目标模型上多添加几个预测头来预测后续token,然后单独训练。
- 对目标模型做序列级蒸馏,用其生成的数据训练草稿模型。
- 将 Target 模型的输出激活值作为 Draft model 的输入,训练 Draft model 预测token。
6. Result
模型设计
作者训练了一个 40亿参数 的草稿模型。该模型与 Chinchilla(目标模型,700亿参数)使用相同的分词器和训练数据,但在架构上做了针对性调整:
| 模型 | 隐藏维度
|
Heads | Layers | Params | 推理速度 (ms/token) |
|---|---|---|---|---|---|
| Target(Chinchilla) | 8192 | 64 | 80 | 70B | 14.1 |
| Draft | 6144 | 48 | 8 | 4B | 1.8 |
核心思路是减层数、不减宽度。层数少,all-reduce 通信开销就低。该草稿模型在16块 TPU v4 上跑到 1.8ms/token,Chinchilla 是 14.1ms/token,快了约 7.8倍。
评估任务
作者选择了两个差异显著的基准任务:
- XSum(摘要生成任务)
- 1-shot prompting
- 共生成 11,305 个序列
- 最大序列长度 128
- 采用 Nucleus 采样(p=0.8)和 Greedy 采样
- HumanEval(代码生成任务)
- 100-shot prompting
- 共生成 16,400 个样本
- 最大序列长度 512
- 采用 Nucleus 采样(p=0.95,温度 0.8)
实验结果
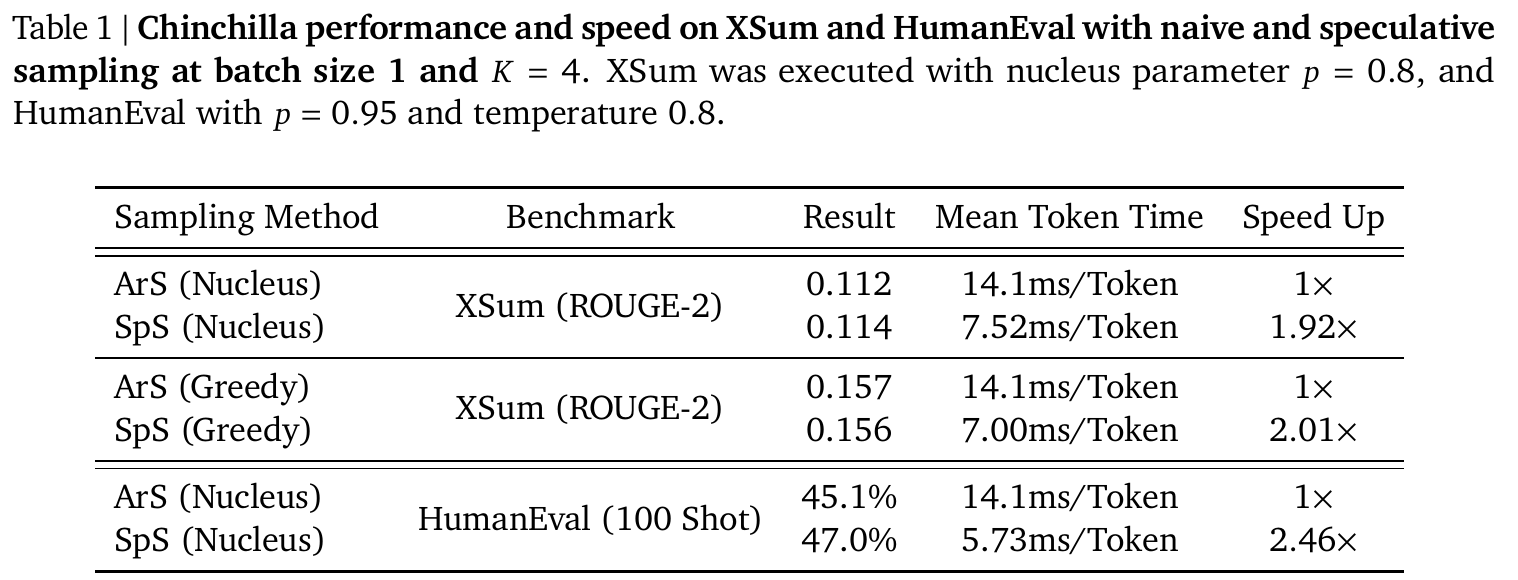
- 分布一致:ROUGE-2(0.112 vs 0.114;0.157 vs 0.156)和Pass@100(45.1% vs 47.0%)的差异在正常范围。论文将此归因于:
- 伪随机种子处理方式不同
- 计算图差异导致的数值误差
- 论文Theorem 1已证明分布理论上等价
- HumanEval 加速更明显(2.46× vs 1.92×)。论文给出的解释:
- 代码包含大量常见子序列(如
for i in range(len(arr)):),草稿模型易于预测 - 代码任务中token分布更集中(词汇表使用偏向特定模式)
- 温度参数(0.8)锐化了概率分布,使两个模型的分布更接近
- 代码包含大量常见子序列(如
- 突破理论内存带宽上限:在HumanEval和Greedy XSum中,加速比超过了“模型参数量/总内存带宽”这一理论上限——因为SpS在一次前向传播中并行验证了多个token,打破了自回归采样的硬约束。
分布式推理优化
因为额外的通信开销吃掉了计算收益,导致了一个7B参数模型在16个TPU上延迟反而高于4个TPU。
- 最优拓扑不匹配:Chinchilla 70B 的最优配置是 16块 TPU v4;一个计算最优的 7B 模型,延迟最低的配置却是 4块 TPU v4(5ms/token)。
- 通信开销超过计算收益:把 7B 模型放到16块TPU上,小模型本身用不了那么多算力,多出来的芯片带来的全是通信开销,反而拖慢速度。
- 延迟不降反升:
论文明确指出,将 7B 模型从 4 块 TPU 扩展到 16 块 TPU 上服务时,延迟非但不会降低,反而会实际增加(actually increases the latency)。
模型架构在分布式环境优化要点:
- 保持宽度(d_model=6144)以维持模型容量
- 减少层数(仅8层)以最小化通信开销