机器学习项目基础设施
机器学习项目基础设施
机器学习过程可以大体上分为三个部分数据管理、模型训练与生产部署。
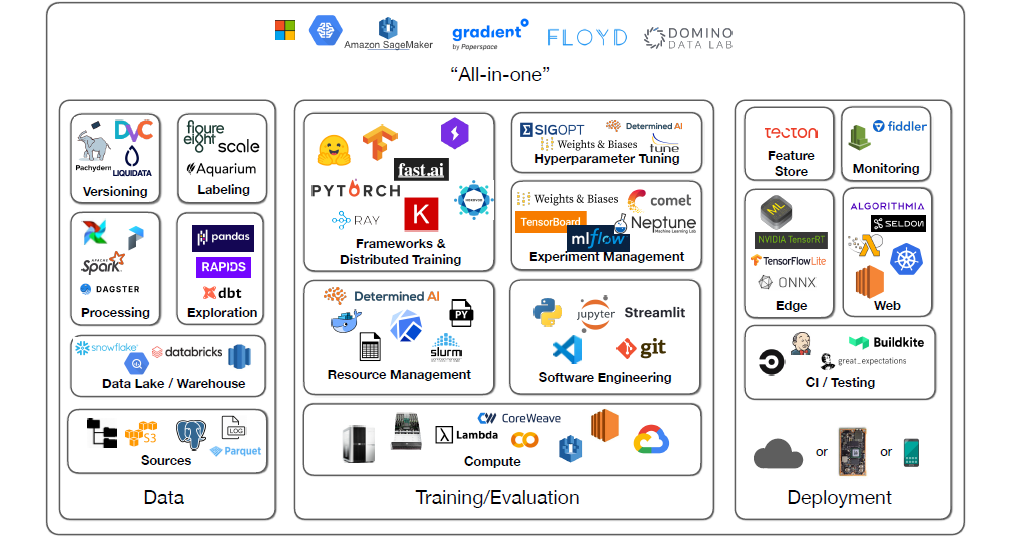
图片来自课程 Full Stack Deep Learning
数据管理
数据源(sources)
数据源负责数据的存储与数据格式,常用的存储方式包括本地的文件系统、服务器上的对象存储。常用的数据格式有HDF5、Parquet 等。
数据湖/数据仓库
负责管理记录数据集,常见的数据湖软件/服务包括有:snowflake、databricks
数据处理
数据处理有很多并行计算的框架
- apache airflow:由 Airbnb 开源的计算框架,可以用来构建 DAG 计算图,实现数据的细粒度并行处理。
- spark:老牌数据流处理框架,支持 Java、Python 在内的多种语言。
- Dagster:和 airflow 一样也是一个数据计算的编排框架
数据分析
- pandas:最常用的数据处理框架
- rapis: 基本上就是支持 GPU 计算的pandas
版本控制
- DVC:全名叫 Data version control,专门负责数据版本控制还有模型版本控制的工具,它的操作基于git,通过对大文件的管理来实现版本控制。
- Pachyderm: Pachyderm 不只是单纯的数据版本控制,还提供了数据生成pipeline的管理。
模型训练
计算设备&服务
本地的计算设备、各种云计算服务
资源管理
Docke、sdetermined AI 等
计算框架&分布式训练框架
深度学习框架:Pytorch、 tensorflow
深度学习库:fast.ai、keras
分布式计算框架:RAY 等
实验管理
- TensorBoard:tensorflow 的可视化实验管理模块,现在独立出来,甚至 pytorch 都对他进行了支持。但是它没有对多个实验的管理能力。
- mlflow:是一款开源的试验管理工具,最大的特点是提供本地的实验管理功能,没有各种收费的云服务版本。
- weights & biases: 是一款综合的实验管理工具,它除了提供实验追踪,还提供了数据可视化、模型调优等功能。但是 W&B 是一款基于网络服务的实验管理工具。
- Neptune.ai comet.ml: 也是基于网络服务的实验管理工具。
超参调试
- SIGOPT
- Determined AI
- Weight & Biases
- Tune
模型部署
CI&测试
- Jenkins
- Gitlab CI
- Circle CI
边缘设备部署
- Nvidia TensorRT
- TensorFlow Lite